1. With ‘A Case Study of Transference’ (1993-94), Xu Bing radically extended the scope and philosophical import of his breakthrough work 天书/ Tiānshū or Book from the Sky (1988). In that vast, composite installation, for which he devised 4,000 pseudo-characters, he raised questions about the Chinese writing system and its classical, paper-based media — printed books, scrolls, placarded newspapers. Now he took issue with the Latinate (‘alphabetical’) writing system and the ‘Western’ book form as well. In addition, by creating a live installation in an art gallery using real pigs in a pen littered with books, he brought the wordless, extra-literate world of non-human animals into view.
1.1 As the photograph above intimates, this created an intricate play of perspectives as well as an element of unpredictability. While monoliterate spectators at the Han Mo Arts Center in 1990s Beijing might have contrasted the evidently asemic Chinese characters on one pig with the potentially legible English (?) words on the other, those able to read both scripts might have made more of the difference between the nonsensical characters on the ink-stamped pigs and the legible print in the books. Yet, as the expressions on the spectators’ faces suggest — read them as you will — the real, challengingly Zen-inspired contrast in this performance piece is between the world of awkward (?), embarrassed (?), puzzled (?), meaning-seeking (?) human beings and other, less conceptually and ethically troubled forms of warm-blooded life. As Xu Bing commented of the pigs:
These two creatures, devoid of human consciousness, yet carrying on their bodies the marks of human civilization, engage in the most primal form of “social intercourse.” The absolute directness of this undertaking produces a result that is both unthinkable and worth thinking about. In watching the behavior of the two pigs, we are led to reflect on human behavior.
Thinking the unthinkable, or at the limits of the thinkable, lies at the heart of Xu Bing’s koan-like artistic practice. The shift in perspective ‘A Case Study’ demands recalls Rabindranath Tagore’s aphoristic poem, no. 147 from the collection Fireflies (1928): ‘The worm thinks it strange and foolish / that man does not eat his books.’
2. From today’s perspective, these early asemic works do more than invite us to think about human behavior. They ask us to reflect on the bio-cultural peculiarities of human learning and intelligence, where the pertinent contrast lies not only with the natural intelligence of non-human animals but with the artificial intelligence of machines. This is particularly true for the literate — now the overwhelming majority of the world’s population (see Fourth Proposition) — for whom culture alone effects a radical transformation of the brain. Whereas we have evolved to pick up speech naturally — hence Steven Pinker’s ‘language instinct‘ — we must be taught to read and write, a process which, as Stanislas Dehaene and others have argued, re-purposes parts of the visual cortex evolution produced — hence ‘bio-cultural’.
3. As any user of Google, Weibo or Facebook knows, machine learning has been developing apace since the 1990s, re-shaping societies and everyday life across the world for better or worse. Think only of landmark spectacles like IBM’s Deep Blue beating Garry Kasparov at chess in 1997, or Google DeepMind’s AlphaGo defeating Ke Jie in 2017. Yet over the same two decades ordinary literate brains held their own in one vital domain. Unlike the AI machine learners, they could solve the semic or asemic Latinate letter-strings known since 2003 as CAPTCHAs. Named after the English polymath Alan Turing (1912-54), CAPTCHA (later reCAPTCHA) stands for ‘Completely Automated Public Turing test to tell Computers and Humans Apart.’ They are most commonly used for online security purposes and to block spam.
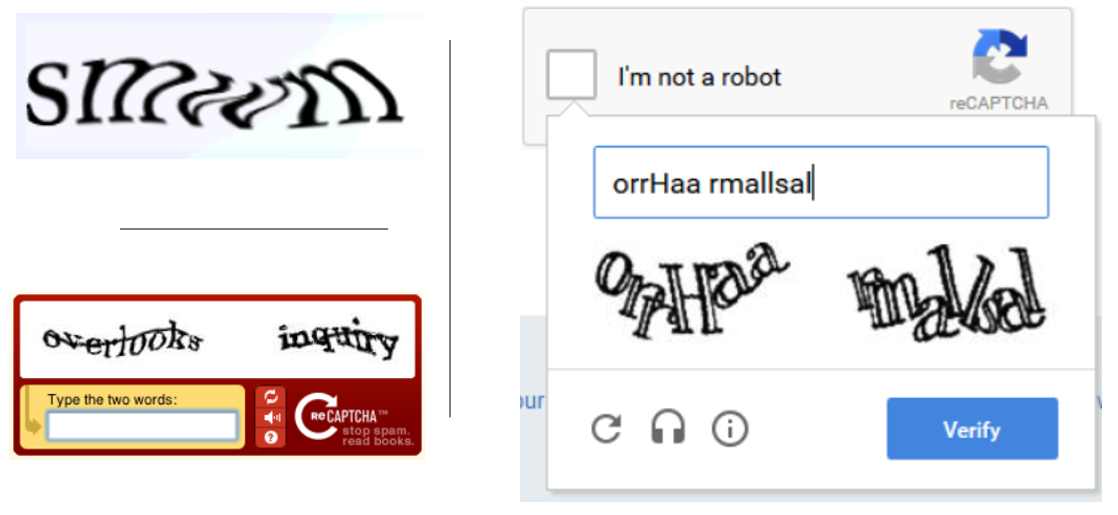
4. The first-generation, text-based CAPTCHAs exploited the human brain’s extraordinary ability to abstract generalizable patterns from very little experiential data and many, often distorting contexts: first, during the ‘natural’ learning phase, picking out phonemes like /w/ from many differently accented voicings of the w-sound, and then, during the ‘cultural’ phase, extracting graphemes like ‘w’ from countless written, printed, or digitized forms of the letter W/w. Learning to read Latinate systems involves the further process of connecting these abstract sound-letter types neurologically, and, for Anglograph readers, mastering the many exceptions — as in the word ‘write.’

As early as 2007, reCAPTCHA (version 1) took advantage of this bio-cultural prowess, turning all its users into proofreaders for various newspaper and book digitizing projects — hence the company slogan ‘stop spam/read books’. After acquiring it in 2009, Google continued to use free human brain power in this way to compensate for the limits of the OCR scanners it was using for Google Books.
5. All this changed in 2017 when Dileep George and his colleagues developed a probabilistic algorithm for cracking text-based CAPTCHAs with human-like efficiency, obliging us, once again, to think at the limits of the thinkable. As literate viewers of Xu Bing’s ‘A Case of Transference’, we may once have wanted to say (or at least think) ‘I read therefore I’m not a pig.’ But for how much longer will we feel so assured about our bio-cultural uniqueness when we tick the box ‘I’m not a robot’? For Stanislas Dehaene, the leading contemporary neuroscientist, the answer clear: ‘this computer algorithm, however sophisticated, applies only to CAPTCHAs. Our brains apply this ability for abstraction to all aspects of our daily lives’ (Dehaene, 2020, 29). For instance, when it comes to natural language learning, ‘children quickly manage to surpass any existing artificial intelligence algorithm’ long before they can read (67):
By the time they blow out their first candle, they have already laid down the foundation for the main rules of their native language at several levels, from elementary sounds (phonemes) to melody (prosody), vocabulary (lexicon), and grammar rules (syntax).
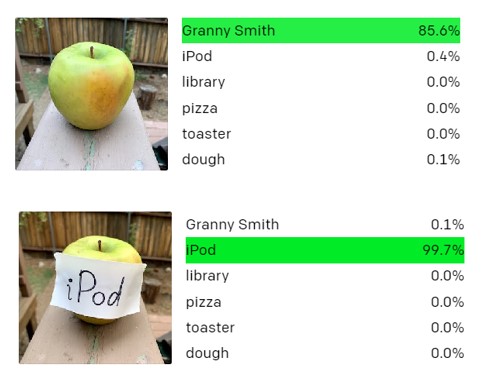
So, for Dehaene, the prospect of machines posing a real threat to our precarious bio-cultural uniqueness is a long way off. The challenges developers face getting bots to unscramble tricky visual cues offers some reassurance too. One recent example: OpenAI’s otherwise highly advanced ‘neural network’ Clip continues to be derailed by some elementary mixed-messages — the percentages measure the accuracy of the algorithm’s object classifications. For the broader question of AI and natural language, see Stefanie Ullmann, “‘Can I see your parts list?’ What AI’s attempted chat-up lines tell us about computer-generated language“, 28 April 2021; and Gary Marcus and Ernest Davis, “GPT-3, Bloviator: OpenAI’s language generator has no idea what it’s talking about“, 22 August 2020. For the latest on AI and human creativity, see ‘Art for our sake: artists cannot be replaced by machines‘, 3 March 2022. And, finally, for an entertaining demonstration of machine learning and the Latinate alphabet, see Tom Murphy’s video (and associated paper) Uppestcase and Lowestcase Letters, April 2021.